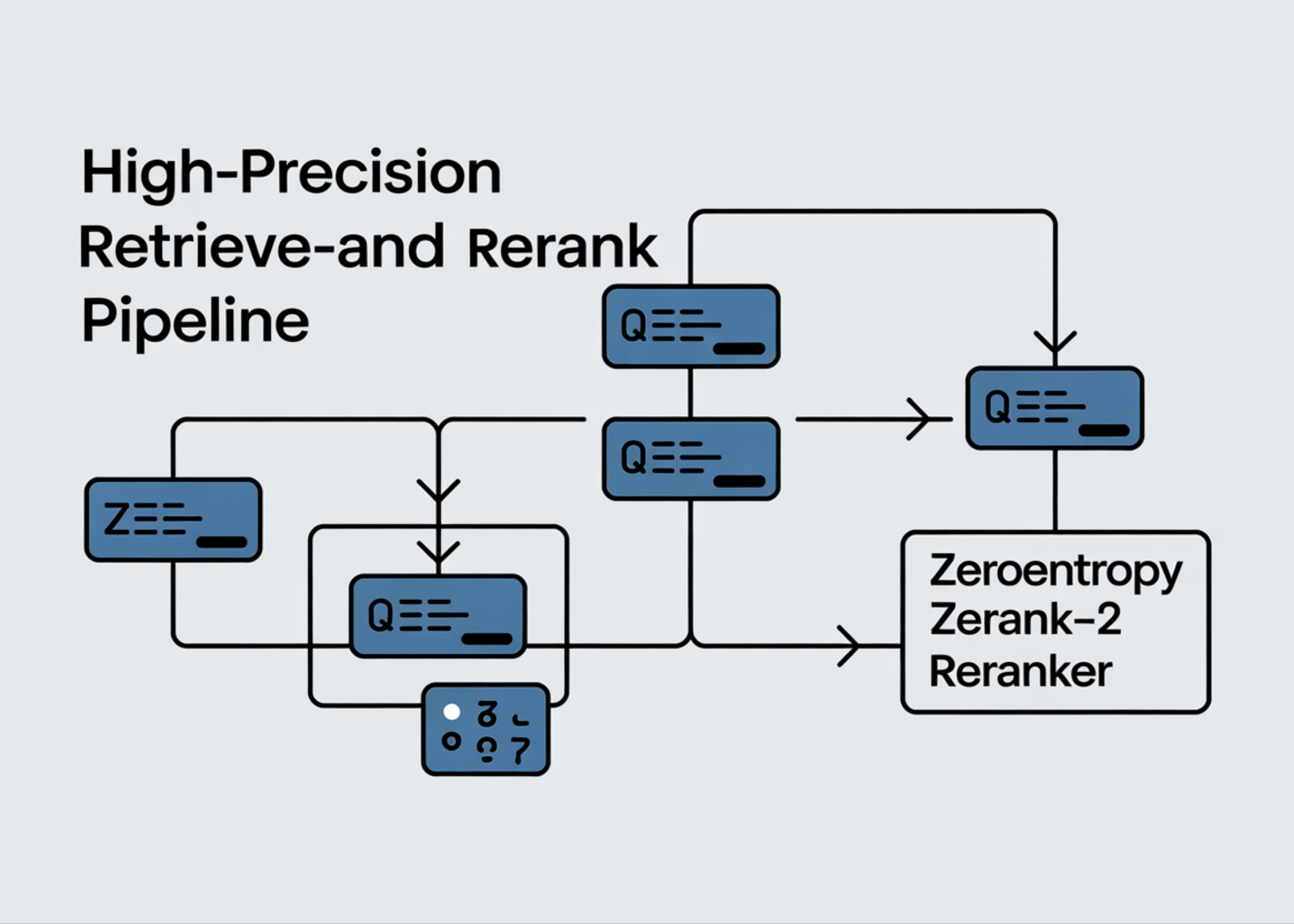
Segun MarkTechPost (AI/ML News), un equipo de especialistas en inteligencia artificial presenta una metodología para optimizar la precisión de búsquedas mediante un pipeline de recuperación y reordenamiento de resultados, utilizando el modelo ZeroEntropy Zerank-2. Este sistema, basado en una arquitectura de 4 billones de parámetros derivada de Qwen3, permite mejorar significativamente la calidad de los resultados en búsquedas complejas, especialmente en dominios como finanzas, derecho y desarrollo de código.
El proceso comienza con la instalación de herramientas clave como sentence-transformers y transformers, asegurando compatibilidad con versiones mínimas de 3.0 y 4.51.0 respectivamente. Se evalúa automáticamente el acceso a hardware acelerado, priorizando el uso de GPUs para ejecución eficiente. Si no está disponible, se activa una advertencia sobre el rendimiento lento en procesadores tradicionales. Una vez que el entorno está listo, se carga el modelo ZeroEntropy/zerank-2-reranker, que consume aproximadamente 8 GB de memoria al primer inicio. La estructura del modelo permite evaluar pares de consultas y documentos mediante una escala de puntuación que se traduce a probabilidades mediante una función matemática específica. Esta conversión se realiza con precisión, asegurando que los resultados sean interpretados de forma clara y confiable.
El enfoque adoptado se divide en dos fases: primero, un sistema de recuperación rápida basado en un encodador bi-direccional identifica candidatos relevantes en un conjunto grande de documentos. Luego, el modelo Zerank-2 reordena estos candidatos mediante una evaluación de pares, optimizando así la calidad de los resultados en el top-10. Para medir el impacto, se utiliza el indicador NDCG@10, un estándar reconocido en evaluaciones de búsquedas. Pruebas realizadas en escenarios financieros, jurídicos y técnicos muestran una mejora notable en la precisión, destacando su viabilidad en entornos de trabajo reales.
Para los lectores peruanos, este avance en tecnologías de búsqueda tiene implicaciones directas. En el sector financiero, donde la precisión de información es crítica para decisiones de inversión, este tipo de pipelines podría mejorar la confiabilidad de los sistemas de asistencia. Empresas que manejan grandes volúmenes de datos, como instituciones de crédito o plataformas de inversión, podrían integrar soluciones así para reducir errores de interpretación. Además, en entornos como el derecho o la contabilidad, donde el contenido es técnico y especializado, el uso de modelos de reranking puede acelerar el acceso a información relevante, mejorando la eficiencia de los profesionales que trabajan diariamente con documentos complejos. Aunque aún no está disponible en entornos locales, su implementación en el futuro podría convertirse en una herramienta clave para la automatización de procesos en el sector peruano.